Fixing the data layer & rebuilding trust across revenue teams.
Field-tested playbooks from Revenue Architects at Fivetran, GitHub, and ISS Shipping.
“Your data is the mind of the AI, it is what it can act on.”
Fixing the data layer became the priority when AI started acting on it
Before AI, a human could quietly detect what was wrong and fix it. Now an agent instantly acts on the quality of your data. That’s because most decisions, humans, analytics and agents consume your data. If your source of truth is siloed or wrong, it produces confidently wrong outputs at scale, burning real dollars and tokens while doing it.




3 playbooks from leading Revenue Architects
Ablla Strainer
Two large Salesforce orgs becoming one consolidated instance, without disrupting the business or the customers during the merge.
“When you’re going through something as big and complicated as a merger, anchor to the principle of first do no harm. It starts with taking care of our customers, and make sure the experience they get from us is never put in jeopardy.”
Where to start
Do a customer mapping exercise. “Who are your customers? Figure that out. Then take it a step further: if your business looks at things through the lens of a hierarchy, can you represent where customers fit? Is it the parent? Is it a child? How do you want that reflected in the surviving CRM?”
How to get started
Start with collaboration. “This should all happen outside of the systems first, so that we have an understanding of what we’re working through, (how you define an account, taxonomy, field mapping) and then it would need to be a very well-orchestrated data migration strategy starting first with accounts.”
Determine surviving account definitions
Recognize Old Spice? It’s a major brand under Procter & Gamble, but it’s not a legal entity. Providers like D&B and ZoomInfo only recognize legally registered companies, so Old Spice never links P&G into a corporate hierarchy.
The records look complete on paper, while your rollups, routing, and GTM run on incomplete context, wherever brands, franchises, and operating units matter more than legal entities.
Ernesto, Chief Technology Officer, on how it works in practice
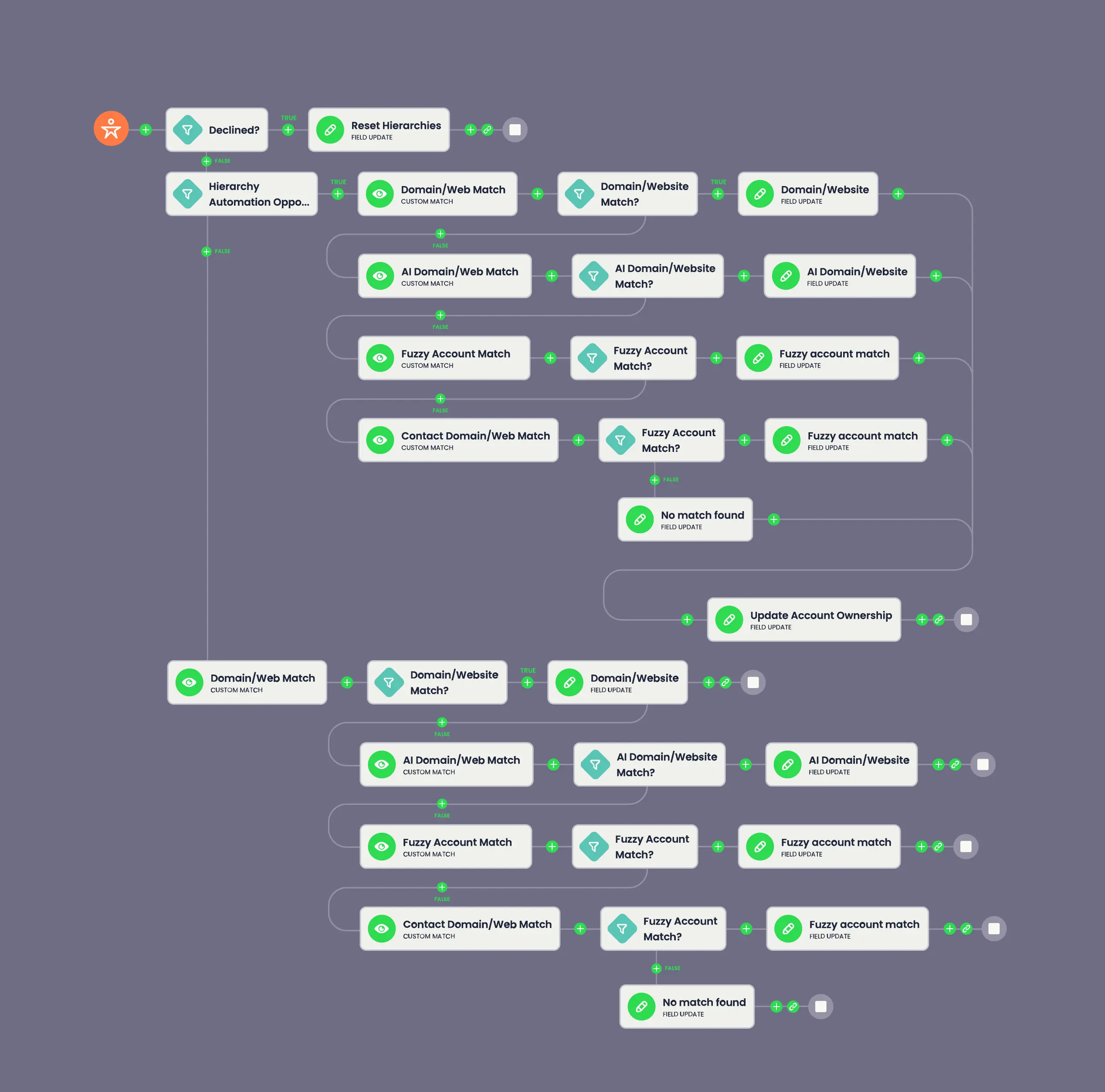
AI corporate family discovery and alignment flow
This flow uses fields populated by a prior AI enrichment flow to identify accounts that are not currently part of a hierarchy but show strong signals they belong to a larger corporate family.
Using domain matching and fuzzy account name logic anchored to existing hierarchy records, the flow evaluates potential relationships for accounts that are not yet represented in the hierarchy.
When a likely relationship is detected, the flow does not force a hierarchy change. Instead, it flags the account through a field update and routes the suggestion into an approval step for manual verification. Once approved, the flow updates the relevant parent-child hierarchy fields, automatically attaching the account to the correct hierarchy using the validated context.
Radu Negru
In a regulated industry, a wrong record isn’t just an internal fire drill. It means a customer-facing error, a mispaid vendor, or a compliance issue.
“In our industry, the correct management of data plays a huge role. Miss a subsidiary in an internal report and that’s a couple of days’ fire drill for the analytics team. Miss one in a customer-facing report and it causes all sorts of issues, including customers losing trust in our data. If we pay the wrong vendor because of stale bank account information, that leads to reputational and even legal issues.”
Human in the loop
“I’m the data governance guy. For me, human in the loop is mandatory and should never be taken off. With critical fields and data points, if it affects compensation, company KPIs and the business, you need human in the loop.”
Keep training material current
“Get basics right, the documentation you’re training AI on is always up to date. Make sure that you have really, really tight guardrails around the data that you’re using to train that AI.”
Treat AI like a maintained asset
“Maintain an AI asset and model registry. Treat it like a software asset: what data trained the model, what the intended use case is, who owns it, and when it was last audited.”
How AI-powered validation thinks
“Does this record meet the rules?”
Checks format against fixed rules. Polished junk, real-looking names and plausible domains have just enough structure to slip through.
“Does this record make sense?”
Instead of relying on fixed rules, Data Agents evaluate inputs as they arrive, interpreting for credibility, context, and completeness before records move deeper into Salesforce.
Jon-Sun Lu
One to two million signups a month arrive through different channels at once, and the rest of the funnel needs something it can use.
“Dirty data in, dirty data out. That really rings true, especially in this kind of funnel. How do you actually get clean data? You need to align with your sales operations team and your CS operations team, because what the field needs and what customer CSMs need also has to start at the very top.”
One data dictionary
“Really aligning all operational teams under RevOps to speak the same language. What’s the data dictionary? We all have to agree. And so each respective team can go back to their acquisition channels to standardize.”
Don’t go it alone
“Don’t try to go at the solution by yourselves, but really knock on the peer’s desk right next to you, the other ops team, and see what they care about. And make sure as you’re architecting your solution, you keep that in mind.”
AI, then confirm
“We have AI that scans all the data and then stages it: here are all the different chances, and then put the human in the loop. Teams under RevOps spot check and say, yep, that’s correct, go for it. We’ve automated a ton of matching, but we’re still making sure our agents use a proper waterfall prioritization.”
How to standardize a record so the dictionary holds
People describe the same role dozens of acceptable ways. “Prod mgr,” “product management,” and “PM” are one role, and rule-based tools can’t tell.
Rule-based tools depend on fixed mappings and exact matches, so they can’t tell that one role is being described three ways.
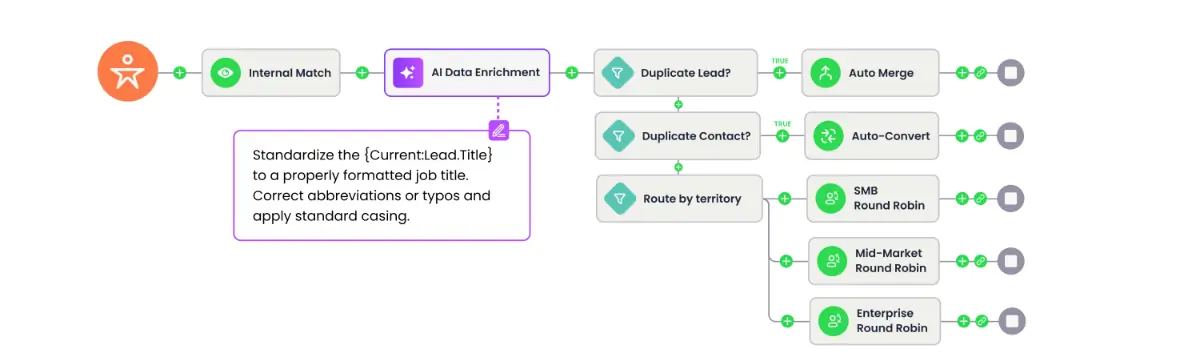
A Data Agents flow step lives inside existing flows and runs whenever a record enters or updates Salesforce.
The top plays every Revenue Architect came back to
Align across teams before you build
Whoever sits at the front of the data stream brings in everyone affected downstream, agrees on what data matters, then designs the solution.
Fix the data layer before speeding up
Ablla’s team slowed account creation on purpose to rebuild a clean data layer before bringing agents back in.
“Slow is steady and steady is fast.”
Keep the human in the loop until trust is earned
Every panelist runs an approve-before-write step. Ablla’s agents post proposed changes to Slack for RevOps to approve, GitHub stages matches for a human to confirm, and Radu treats it as non-negotiable for compensation and KPI fields.
“Don’t take off the training wheels.”
Apply the same rigor to build-vs-buy, even when building is free
The new ease of building doesn’t change the questions you ask of any tool: what’s the support model, who owns it, what’s the roadmap?
“Just because you can vibe code it in a weekend doesn’t mean you should maintain it forever.”
Keep the documentation your AI trains on current
Stale policies and stale data become stale instructions. Radu’s rule: when a policy changes, take the old version out of the repository so it can’t confuse the agent or the person reading it.
No agent is smarter than the data it runs on.
These revenue leaders all agreed on the order of operations: get the basics right, align teams, keep a human in the loop, and treat your data as an asset everything else depends on. While other AI agents consume, Data Agents do that work to continuously improve data inside Salesforce, with you deciding what gets written.
Hierarchy Mapping
Builds corporate structure from ownership and operating relationships, including subsidiaries your provider doesn’t track.
Match Intelligence
Finds account records that represent the same company, including matches static rules and providers would miss.
Enrichment
Fills missing fields from your calls, contracts, the web, and our proprietary database, tailored to how you sell.
Normalization
Standardizes names, titles, and fields across every record so matching, reporting, and segmentation work as needed.
Validation
Catches bad records and verifies accuracy before anything is written. No provider is 100% correct.
Classification
Applies your industry, vertical, segment, and territory definitions to every account so data reflects how you sell.
Detection
Monitors news and filings for M&A and restructures so your records reflect the market as it happens.
Account Scoring
Scores accounts for ICP fit, prioritization, and survivorship so reps know which records to focus on.
Nothing writes without your say
You decide what gets written, when, and by what rule.
This is the human-in-the-loop principle, built in. Every decision is logged, and every output carries a confidence score with its sources and a reasoning narrative. The approval step stays in place for as long as you want it there. As Ablla put it, you can loosen the approval as trust builds, but you don’t have to.
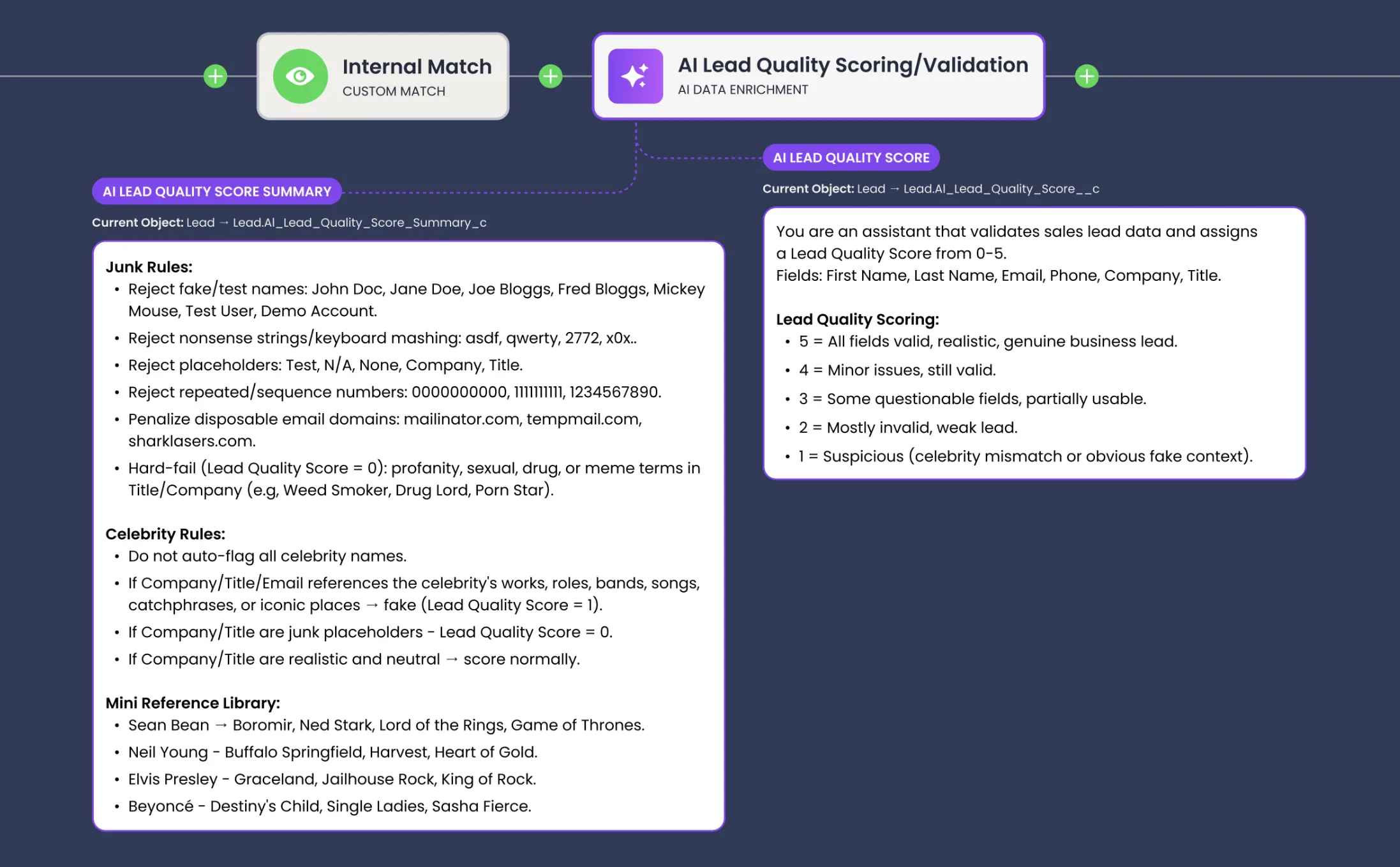
“At Traction Complete, we use data agents internally. My favorite use case is identifying junk leads — looking for celebrities, test names, fictional characters. It would be painful to do that programmatically, but I can ask an AI. And we have another tool for enrichment that’s very much human in the loop: agents enrich data in front of you, you evaluate and iterate on your prompts, then put in what you agree with.”
What are Data Agents?
A growing set of AI agents that work inside Salesforce and fix the data itself — the broken hierarchies, the duplicates, the gaps and errors that pile up over time. Each runs natively in your org. You choose how much they handle on their own and how much goes to a review queue.
See Data Agents live
“Join a live demo of Data Agents, where we talk more about those specific scenarios like how to use Data Agents for deduplication, standardizing, validating, classifying, normalizing, and enriching.”