What do a misrouted lead, an inaccurate pipeline, and an annoyed sales rep have in common? Salesforce data cleansing could’ve prevented all three.
We get it — cleaning Salesforce data isn’t the most exciting part of RevOps. Nobody gets riled up over a mid-week chore, but everyone feels it when the data’s a mess.
If your CRM is chock full of duplicates, outdated records, and missing fields, it doesn’t matter how good your GTM strategy is. The mess will compound over time and hit you where it hurts most: missed revenue, misaligned teams, and skepticism behind the numbers.
The good news is you don’t need to clean everything at once.
With the right mix of proactive habits, reactive fixes, and smart automation, you can bring order to the chaos — and keep it that way.
What is Salesforce Data Cleansing?

Salesforce data cleansing is the process of identifying and resolving inaccurate, incomplete, duplicate, and outdated data in your Salesforce CRM. It’s a critical step in protecting go-to-market (GTM) data integrity, ensuring teams can trust the information inside the system, and supporting strong RevOps data management.
But what makes Salesforce data cleansing so uniquely challenging is the volume of interconnected objects and automated processes that depend on clean data to function correctly.
From lead-to-account matching to mass territory reassignment and reporting, even a small data issue — like a misspelled company name or a missing field — can disrupt workflows and trigger errors.
That level of dependency means cleanup can’t be treated like a quarterly chore or a one-off admin task. As such, keeping your Salesforce data environment clean is a continuous effort that requires two tracks:
- Proactive strategies that focus on prevention. These include standardized field inputs, validation rules, and clear naming conventions.
- Reactive strategies that identify and fix what’s already broken, such as bulk deduplication to merge duplicate records at scale, and field restoration to fill missing details like industry and revenue.
Together, these two strategies help create a Salesforce environment that’s clean, connected, and ready to support evolving GTM needs.
Why is Salesforce Data Cleansing Important? 5 Reasons
Clean data keeps your GTM engine running smoothly. Here’s why it’s so impactful:
1. Accurate data powers reliable lead routing
Speed-to-lead is the first competitive moat in any GTM motion, but lead routing logic is only as good as the data it relies on. If specific fields like state, employee count, or industry are wrong or missing, the entire process breaks down.
And today’s routing demands don’t end at the field level. They factor in ICP fit, intent scores, the current opportunity owner, and even which level of an account hierarchy a lead belongs to. So when a single data point is off, you risk your whole sequence misfiring.
Often, the largest downstream failures aren’t even caused by data quality flaws of the same magnitude.
Here are three examples:
| Data Quality Flaw | Downstream Failure |
|
Near-duplicates (“Acme Corp.” vs. “Acme Corporation”)
|
Duplicate outreach and rep conflict
Matching engine interprets them as separate companies, leading to duplicate outreach and rep conflict.
|
|
Stale territory IDs after a realignment
|
Leads land in catch‑all queues
Rules fire, but the lead gets stamped with last quarter’s ID, causing it to land in a catch‑all queue.
|
|
Orphan child accounts with no parent
|
Unassigned leads trigger SLA timers
Hierarchy‑based rules can’t resolve the owner, causing SLA timers to start on an unassigned lead.
|
Enterprise technology leader Cisco felt these problems at scale.
With millions of records and thousands of daily leads, their routing tool produced more than 60% inaccurate assignments.
After a one-time cleanse (dedupe and standardize core fields) and leveraging Traction Complete’s hierarchy-aware matching, Cisco re-scored 2 million records and now routes leads with 100% accuracy without manual lead triaging.
2. Forecasting, reporting, and automation all depend on clean data
Pipeline forecasts and reporting decks all pull from the same opportunity data in Salesforce. If a lead isn’t matched to the right account, or if child subsidiaries aren’t rolled up to a global parent, every downstream report and model inherits that error.
Here’s what can happen to your forecasting and reporting if you’ve got messy data:
- Attribution drift. When records aren’t properly cleaned and matched, you risk crediting revenue to the wrong segment, channel, or rep. When it’s time to distribute the budget, leaders are doing so in a vacuum, possibly cutting what’s working and doubling down on what isn’t.
- Misunderstanding retention and expansion. Net Revenue Retention (NRR) appears weaker because expansion in one subsidiary is offset by churn in another, even though the net at the parent level is positive.
- Overstating new logo wins. You may incorrectly tag subsidiary deals as “net-new,” which can skew acquisition metrics and distort marketing ROI.
- Misallocating resources. Territory models look unbalanced, leading to uneven assignments and poor coverage.
And you don’t just need clean data for accurate reporting — it’s also what keeps your automation firing in the right place, at the right time.
Here’s what can happen to your automation when data is unreliable:
- Hot leads go cold. Scoring models fail to recognize a high-intent lead because a critical field (like industry or employee count) was left blank, so no routing or follow-up sequence gets triggered until it’s too late.
- Wrong plays on the wrong accounts. A workflow to prevent churn fires on an active, healthy customer because their status field was incorrectly updated during a data import.
- Churned customers. An at-risk alert is sent to a generic, catch-all queue instead of the account owner because the owner field was overwritten during a territory realignment.
Ultimately, you end up with forecasts, reports, and automated processes that are accurate in name only, because they’re all built on shaky foundations.
GTA Homes, one of Ontario’s largest real estate brokerages, had 170,000 duplicate leads that slowed their Salesforce workflows to a crawl.
After tackling the problem with Complete Clean, they cut their duplicate record count by 57%, streamlined operations, and uncovered new productivity gains.
See how you can do the same
3. Unreliable data breaks trust in your CRM
It comes as no surprise that dirty Salesforce data slows execution and creates inconsistencies across your GTM motions. But what’s often overlooked are the knock-on effects this has on your team and their morale.
When reps can’t rely on the data in front of them, they start to second-guess every record, report, and dashboard. Over time, they rely less on Salesforce and more on their own offline trackers and spreadsheets, further fragmenting the truth.
Leaders face the same problem, making decisions based on gut feel or anecdotal feedback because they no longer trust the numbers.
4. Bad data adds costs and eats into your revenue

Bad Salesforce data drains your revenue and resources, with studies revealing that the average company loses 12% of its annual revenue to dirty data.
And more often than not, the culprit isn’t one glaring mistake, but a steady drip of inefficiencies that compound across the business:
- Storage costs creep up. Salesforce storage isn’t cheap. As duplicates pile up, so do your monthly costs.
- Missed revenue capture. Duplicate and incomplete records hide upsell and renewal opportunities, which means they don’t make it to the pipeline.
- Operational slowdowns. Overloaded databases slow report generation, delay list pulls, and increase load time for reps, reducing the time they spend selling.
- Increased resolution costs. The longer duplicate data stays in Salesforce, the more time, tools, and manual labor it takes to fix it later.
Windstream, a leading communications and software company, reduced its record count from 4 million to roughly 500,000 — an 87.5% drop that translated into significant savings on Salesforce storage costs.
Discover how
We’ve become infinitely more effective… we went from 4 million records down to ~500,000. It’s helping drive strategy for every side of our business
Scott E, VP of Sales Operations at Windstream Enterprise
5. Dirty data damages the customer experience
When records are inconsistent or duplicated, it’s not just your internal processes and teams that suffer. Your customers take notice, too.
Here are just some of the knock-on effects:
- Onboarding stalls. A customer success automation meant to onboard new customers fails to fire because the new record doesn’t meet the trigger criteria due to inconsistent naming or missing fields.
- Renewals get confusing. Two reps contact the same person about renewing because duplicate records have slightly different contract dates, confusing the customer and undermining their trust in your organization.
- Compliance violations. Fields like “Opt-Out” or “Do Not Call” get overwritten during a merge, potentially violating compliance laws like CCPA, CASL, and GDPR, which leads to costly fines.
- Mistimed and awkward outreach. Customers get renewal reminders or upsell offers far too early — or after they’ve already renewed — because outdated or duplicate records trigger the wrong timeline.
The YMCA of San Diego County faced a growing challenge — more than three-quarters of its records were duplicates, making it harder to track member interactions and deliver a great experience.
With Complete Clean, they slashed duplicates by over 75% and rebuilt trust in their data.
See how they did it
The Two Pillars of Salesforce Data Cleansing: Proactive and Reactive
Clean Salesforce data is undoubtedly important, but how do you even get started on such a behemoth of a project?
Tackling it all at once is overwhelming — and unnecessary.
The key here is to treat Salesforce data hygiene like dental hygiene: mixing daily brushing with periodic deep cleanings at the dentist to address issues you couldn’t catch yourself.
That’s why the high-functioning teams ensure data hygiene with a two-pronged approach:
- Proactive cleansing. Stopping bad data before it enters Salesforce through standardization, validation rules, and duplicate prevention.
- Reactive cleansing. Finding and fixing existing issues like duplicates, incomplete fields, and outdated records before they impact routing, reporting, and automation.
These approaches work together.
Proactive measures shrink the volume of issues you’ll ever need to fix, while reactive processes catch the ones that inevitably slip through.
In the following sections, we’ll explore each approach in detail, outline their limitations in native Salesforce, and show how the right tools can strengthen your data hygiene program.
Proactive Salesforce Data Cleansing Strategies

If reactive cleaning is your trip to the dentist, proactive cleansing is brushing and flossing your teeth every day.
Another way to think about it is like having a bouncer at the door who checks IDs and stops troublemakers before they get in.
In Salesforce, that translates to having good habits, routines, and guardrails in place so bad data never makes it in.
Effective proactive Salesforce data cleansing strategies include:
Field standardization
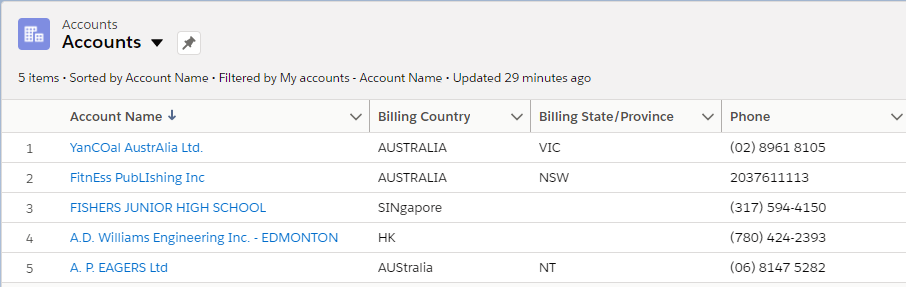
Standardization is the process of making sure data gets entered and stored consistently. So instead of having multiple versions of a state or job titles written in dozens of variations, you enforce a single, predictable format.
Beyond making your data look neat and pretty, it ensures automation, segmentation, and reporting don’t misfire because of inconsistent inputs.
In Salesforce, you can enforce standardization using before-save flows, formula fields, or tools like Complete Clean.
Implementation tips:
- State and country picklists: Turn on Salesforce’s State and Country/Territory picklists to normalize global data entry. Without this, you’ll inevitably end up with a mix of “CA,” “Calif.,” and “California” that’ll wreak havoc on your territory assignments.
- Phone formatting. Consider using Salesforce Record-triggered Flows to auto-format phone numbers into E.164. This ensures consistency across records, boosts match rates, and makes integrations with tools like Outreach or ZoomInfo seamless.
- Job titles. Create a standardization routine via Flows or custom APEX that maps common variations to a controlled set of values for persona targeting.
- Normalize before enrichment. Data imports and enrichment providers like D&B can bring in bulk data with firmographics, hierarchies, and contact info, but both approaches prioritize speed and completeness over consistency. To prevent compounding errors, run batch normalization jobs before enrichment.
Pro Tip: Automatically Standardize Any Salesforce Field with Complete AI
Instead of relying on reps or Flows to catch every inconsistency, Complete AI can automatically standardize critical fields — like phone numbers and job titles — as records enter Salesforce.
That means no more mismatched formats or broken routing logic, and reps always work from clean, reliable data.
WATCH: How to Automate Phone Number Cleanup with Complete Leads and AI
Validation rules
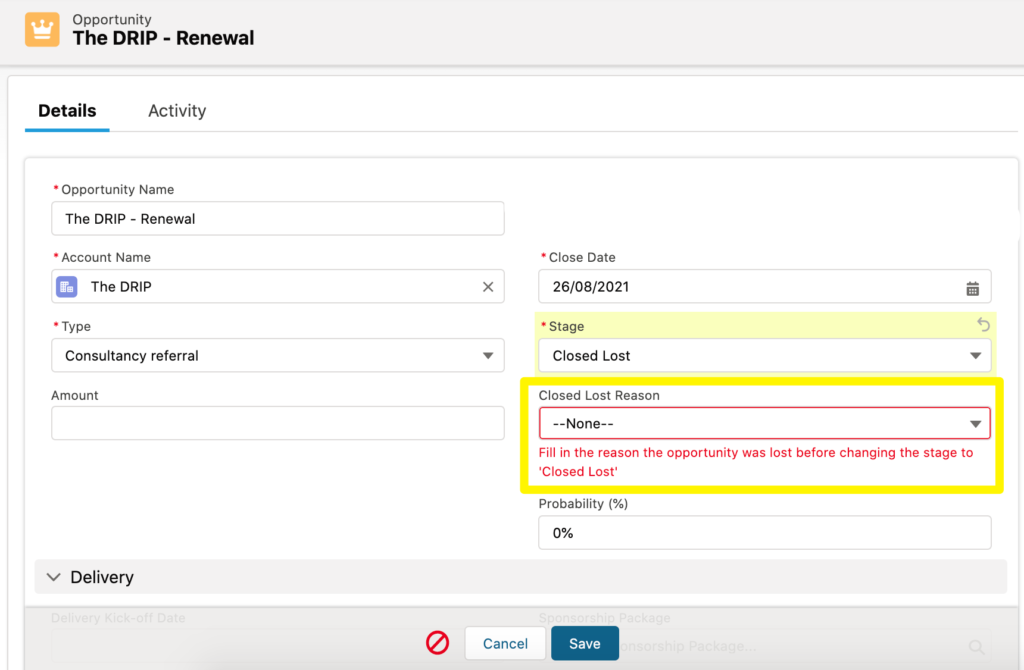
Validation rules act as checkpoints, preventing reps and integrations from saving incomplete records that would create downstream issues for reporting, routing, and forecasting. But misuse can frustrate reps and cause workarounds that introduce more bad data.
The goal is to balance data quality with user experience so the rules actually get used.
Implementation tips:
- Critical fields only. Require only high-value fields like Industry, Territory, or Contract Date before saving. But don’t overdo it, as making 10+ fields mandatory will push reps to enter junk or “n/a” jujst to move forward.
- Conditional validation. Tailor rules to the business context. For example, require “Close Date” only for opportunities marked “Closed Won” or “Contract Sent.” Again, this pushes reps to actually fill out information without bogging them down with irrelevant requirements.
- Always test validation rules. A common mistake is building rules that clash with integration feeds from tools like Marketo. Before pushing them live, test your rules against automated data sources to make sure you’re not blocking critical syncs.
Pro Tip: Use AI-Powered Validation to Automate Data QC
Traditional validation rules can’t tell if “Santa Claus” at “test@test.com is a real lead, but AI can.
With Complete AI, you can flag fake names, placeholder emails, and nonsense companies in real time, keeping junk out of Salesforce before it clogs reports and wastes rep time.
WATCH: How to Validate Records in Salesforce Using Complete Leads and AI
Duplicate prevention logic
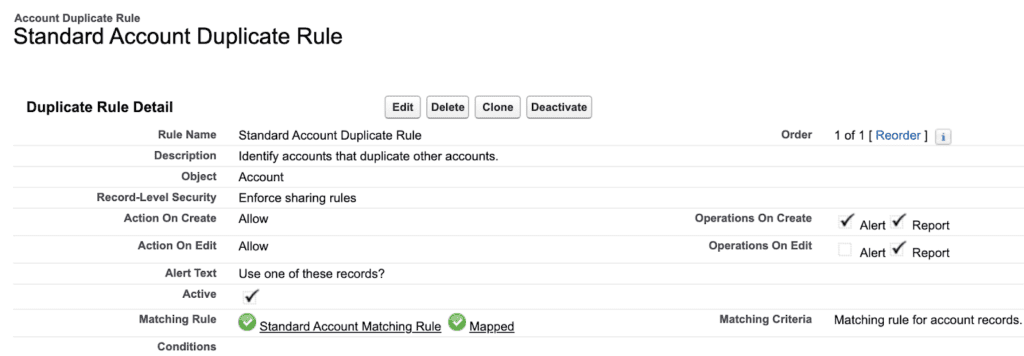
Duplicate prevention logic keeps your Salesforce org clean by ensuring each company or contact exists as a single record, not scattered across near-duplicates. Native matching and duplicate rules manage this by flagging potential duplicates as users create them.
Implementation tips:
- Use fuzzy matching. Fuzzy matching (Soundex, Exact, Email, Phone) can catch slight variations like “ABC Inc.” vs. “ABC Incorporated.”
- Duplicate jobs. Schedule deduplication jobs to run at off-peak hours to catch records that slipped past. Consider starting with “Report Only” mode so you can audit the matches before merging them.
- Set survivorship logic. Define clear criteria for which fields to keep during merges. There might be cases where you would want to preserve the most recent email address over the last modified activity date, or vice versa.
- Use a third-party tool and/or custom logic. Native Salesforce duplicate rules (more on this later) only flag exact matches. So common edge cases like spelling variations or regional differences (Colour vs color) in company names will slip through without a third-party tool or custom APEX.
Pro Tip: Normalize Job Titles (and More) with Complete AI
Rule-based tools can’t keep up with the endless ways people enter titles, industries, or companies. But Complete AI can interpret context and standardize fields in real time — unlocking cleaner matches, smarter routing, and faster speed-to-lead without endless rule-building.
WATCH: How to Normalize Salesforce Fields with Complete AI
What about native proactive Salesforce data cleansing tools?
Out-of-the-box Salesforce comes with its own set of proactive measures, but they also have some well-known limitations:
- Narrow matching criteria. Duplicate rules can’t handle multi-criteria or fuzzy matching, so “Acme Corp” vs. “Acme Corporation” with the same domain can slip through.
- No bulk cleanup capabilities. Native Salesforce tools focus on prevention, but they can’t mass-merge or fix legacy issues without manual work.
- Limited rule enforcement on imports and integrations. Bulk list uploads, API feeds, and syncs from external tools can skip duplicate and validation checks.
- Manual intervention required. Field accuracy checks stop bad inputs, but won’t resolve already missing or inconsistent data.
Over time, these limitations and blind spots compound, necessitating the very cleanup projects you were trying to avoid in the first place. And once bad data is in, Salesforce doesn’t offer a native, large-scale way to clean it up without manual intervention.
Taking Salesforce’s proactive cleansing further
Native tools are good at stopping some bad data at the door, but they won’t catch everything — and they definitely won’t fix what’s already inside.
Strengthening this layer with smarter, always-on prevention ensures your data stays accurate no matter how it enters Salesforce, whether through manual input, bulk loads, or integrations.
Automated tools like Complete Clean help do just that by:
- Running duplicate detection on any Salesforce object at the time of record creation or import, no matter if the source is manual entry, a bulk list load, or an integration feed.
- Applying customizable survivorship rules so if a duplicate is found, you automatically keep the best value for each field instead of overwriting good data.
- Catching near-duplicates through multi-criteria matching (e.g., domain + company name + phone), preventing fuzzy matches from passing undetected.
- Operating entirely inside Salesforce, so there’s no exporting, syncing delays, or security risks from moving your data outside the platform.
The result? A proactive, Salesforce-native layer of protection that works in real time and across all your data entry points.
| Native Salesforce tools vs Complete Clean | ||
|---|---|---|
| Native Salesforce Tools | Complete Clean | |
| Duplicate Detection | Basic duplicate rules with limited matching (mostly exact/single-field). | Advanced fuzzy + multi‑criteria matching across any object (name + domain + phone). |
| Bulk Cleanup | No mass‑merge; relies on manual Data Loader work. | Mass‑merge thousands with guided, no‑code workflows. |
| Survivorship Rules | No configurable field‑level retention logic. | Custom survivorship, field‑by‑field retention, multiple tiebreakers. |
| Imports & Integrations | Rules can be bypassed by list uploads, APIs, MAP syncs. | Enforces cleansing & dedupe across imports, integrations, enrichment. |
| Ease of Use | Admin‑heavy; needs Flow/Apex or manual processes. | 100% Salesforce‑native, guided UI for admins & ops — no code. |
| Ongoing Maintenance | Periodic cleanup projects as issues accumulate. | Continuous proactive + reactive cleansing keeps data clean. |
| Security & Compliance | Cleanup often requires exports (added exposure & overhead). | Data never leaves Salesforce — remains inside your org. |
Reactive Salesforce Data Cleansing

Proactive habits keep most issues at bay, but even the cleanest Salesforce environments build up plaque over time. Old imports, API feeds, and user entry errors (even with picklists) can still slip through.
Reactive cleansing fixes these data quality issues after the fact. It’s like having a dentist scrape away all the calculus and buildup that your regular brushing and flossing can’t touch.
Examples of reactive Salesforce data cleansing strategies include:
Mass deduplication
Mass deduplication is the process of identifying and merging duplicate records that already exist inside Salesforce.
Unlike preventive measures that stop duplicates at entry, this is about cleaning up historical data that slipped through the cracks through list uploads, enrichment syncs, or reps entering slightly different variations of the same account or contact.
In practice, reactive cleansing involves running duplicate jobs in Salesforce Setup, pulling reports of potential matches, and reviewing merge candidates side by side to decide which values to keep.
We’ve already talked about duplicate rules, matching rules, and duplicate jobs in our proactive cleansing section (the native guardrails that stop dupes as they enter), but the process looks different for reactive mass deduplication since you’re dealing with a backlog of records that already exist.
Here’s what the mass deduplication process looks like natively in Salesforce:
1. Identify duplicates with Duplicate Record Sets
- When Duplicate Jobs run, Salesforce creates Duplicate Record Sets that group suspected duplicates together.
- These sets become your working list for reactive cleanup.
2. Manually merge small batches
- From a Duplicate Record Set, click into the records and use the standard merge wizard (available on Accounts, Contacts, and Leads) to consolidate up to three records at a time.
- This tool lets you pick which fields to keep for each record.
3. Handle large data volumes with Data Loader
- Export duplicates to a CSV (from Duplicate Record Sets or a custom report).
- Clean and map the data externally (decide your “survivorship” field values in Excel/Sheets).
- Re-import using Data Loader to update master records, then mass delete the leftover dupes.
4. Log and audit
- Use a custom report or export of “merged” vs. “deleted” records to show what was consolidated and preserve an audit trail.
- Store a backup CSV of original duplicates before deletion.
Implementation tips:
- Start with a duplicate audit. Build a report (in a CSV or spreadsheet) filtered on likely dupes (e.g., accounts sharing the same domain or contacts with matching phone numbers) to size the problem up before launching a cleanup.
- Batch your cleanup. Break large Salesforce data cleansing projects into smaller waves by territory, account owner, or creation date so you don’t overwhelm reps with sudden record changes.
- Preserve history. Export a backup of duplicates to a CSV before merging, so you can restore activity or values if you mistakenly overwrite important data with a merge.
Data enrichment updates
Legacy records lose their usefulness over time.
Accounts with no industry, leads with outdated emails, and contacts with missing territories all limit segmentation and make it harder for teams to prioritize.
But data enrichment updates through third-party data providers like Dun & Bradstreet and Zoominfo can breathe new life into these stale records by filling in the blanks with current firmographics, updated entails, and account hierarchy context.
Implementation tips
- Identify the biggest gaps. Use Salesforce Reports or Einstein Data Detect to surface fields with missing values, like Industry or Territory, that directly affect routing and reporting.
- Target strategically. Start enrichment with open opportunities and active customers so sales teams immediately benefit, then move on to older or lower-value records.
- Use waterfall enrichment. No single provider is perfect, so prioritize enrichment sources in order of reliability (e.g., ZoomInfo for contacts, D&B for firmographics) and configure enrichment flows to pull from the next-best source if the first one can’t fill a field.
- Mix and match providers. Play to each provider’s strengths by using one source for specific fields (e.g., D&B for revenue and employee count, ZoomInfo for decision-maker emails). This prevents one vendor’s weaknesses from cascading into your org.
- Validate before updating. Review enrichment outputs or run normalization rules so conflicting values from different providers don’t introduce new errors.
Pro Tip: Keep Firmographics Current with AI-powered Hierarchies
Third-party data providers often lag behind reality.
If Dick’s Sporting Goods acquires Foot Locker, that deal might hit news headlines today, but won’t show up in third-party data provider enrichment feeds until much later.
But Complete AI can tap into public news, data sources, and LLMs to detect those changes as they happen, automatically suggesting hierarchy updates in Salesforce so your GTM teams always have the most up-to-date enterprise view.
WATCH: Built for your GTM – AI Account Hierarchies
Data Import Wizard
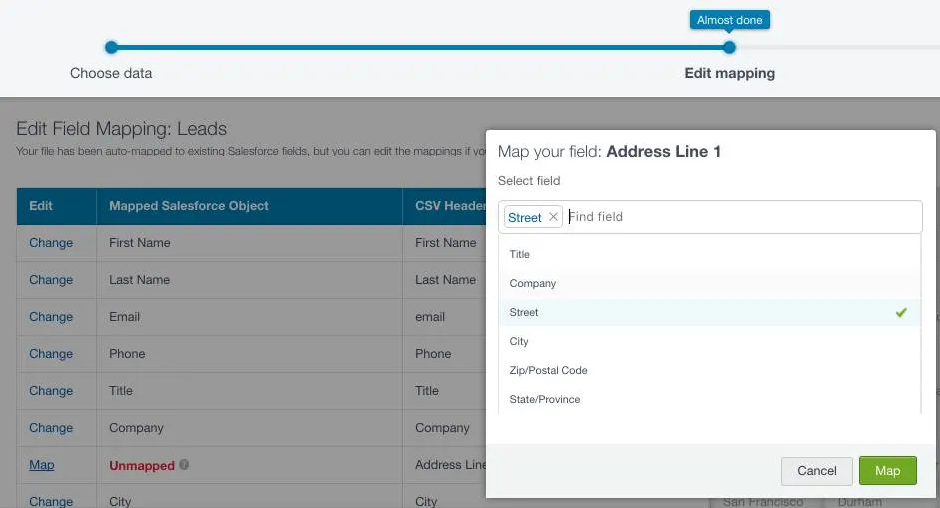
The Data Import Wizard is Salesforce’s built-in tool for loading and updating records in bulk. It’s best for smaller cleanup projects (with a cap of 50,000 records) where you need to correct or enrich data that’s already in your org without relying on technical tools like Data Loader.
Common use cases include patching missing industries, updating territories, or re-uploading corrected event lists.
While it’s not designed for deep deduplication or normalization, it gives you a quick way to run targeted fixes.
Implementation tips:
- Prepare your CSV first. Clean and standardize data in Excel or Google Sheets before import, since the Wizard won’t reformat or dedupe values for you.
- Map carefully. Use the field mapping screen to align your CSV fields with Salesforce fields, and double-check picklist values to avoid errors.
- Test in small batches. Start with a smaller file (a few hundred rows) to validate mappings and results before importing the full dataset.
- Review error logs. The Wizard generates error files for failed rows, so use these to fix issues and re-upload corrected records.
- Plan your cleaning. Data Import Wizard has a hard limit of 50,000 records, and it doesn’t support all objects. You also need to pre-clean your data before uploading, since it doesn’t normalize or dedupe for you.
- Know the limitations. In addition to the 50,000 record cap, there’s a 100MB cap on imported files and a 32MB cap on zip files. Each imported file also has a limit of 90 fields.
Data Loader
For larger and more complex cleanups, Salesforce’s Data Loader is the go-to native tool.
Unlike the Data Import Wizard, it can handle millions of records at once and supports more objects, including many custom ones. Because it works at scale, it’s the tool most admins use for major deduplication projects, CRM migrations, and sweeping field corrections.
Implementation tips
- Use SOQL queries. Filter your export with SOQL to precisely target the records you want to clean, rather than pulling an entire object.
- Prepare and transform data externally. Run corrections or standardization in a CSV or a staging database before re-importing.
- Review success and error files. After each run, check the generated logs to confirm which records were updated and which failed — then fix and re-run if necessary.
- Choose the right operation. Decide whether you’re inserting, updating, upserting, or deleting records, and keep your CSV structured accordingly. For example, use upsert when refreshing enriched firmographics to avoid creating duplicates and delete to remove leads that no longer have valid emails.
What about native reactive Salesforce data cleansing?
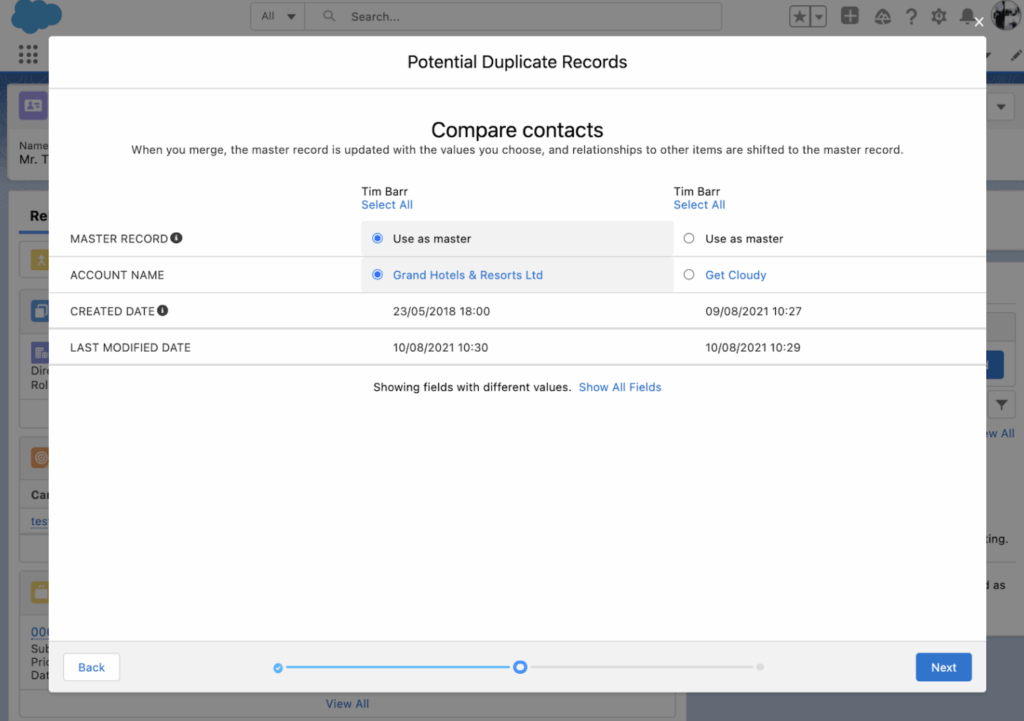
Native Salesforce offers several tools to help you clean up existing data: Duplicate Jobs, the Merge Wizard, the Data Import Wizard, and Data Loader.
These tools can work in a pinch, but they’re manual, time-consuming, and quickly show their cracks when you’re dealing with enterprise-scale data. For most Salesforce admins, reactive cleansing natively becomes an endless cycle of exports, spreadsheets, and reimports.
Here are the biggest challenges with relying only on Salesforce’s native capabilities, and why it might not be the silver bullet you expect:
- Limited merge capacity. Salesforce only allows merging up to three records at a time, and only for standard objects like Accounts, Contacts, and Leads. There’s no way to mass-merge thousands of duplicates in one run, nor to dedupe custom objects.
- Manual field selection. Every merge requires you to manually choose which field values to keep. There are no survivorship rules or automation to prioritize the most recent, most complete, or most accurate data. This makes large deduplication projects painfully slow.
- No scalable bulk processing. While Duplicate Jobs or Reports can surface stale, incomplete, or conflicting records, fixing them means exporting to CSV, cleaning the file offline in Excel or Sheets, and reimporting it through Data Loader or the Import Wizard.
- Data Import Wizard limitations. The Wizard caps at 50,000 records per file, doesn’t support all objects, and requires data to be pre-cleaned before upload. It also has hard file size limits (100MB per CSV, 32MB per ZIP) and won’t dedupe or normalize on the fly.
- Data Loader tradeoffs. Data Loader supports millions of records and more objects, but it comes with its own headaches: SOQL queries to filter exports, external transformations, and the risk of overwriting correct values when reimporting.
- High risk of human error. Native tools depend on manual clicks, mapping, and judgment calls. It’s easy to overwrite good data with bad, create duplicate records during imports, or break relationships between accounts, contacts, and opportunities.
- No continuous safeguard. These tools clean up today’s mess, but they don’t prevent tomorrow’s. Without automation, duplicates and stale records build up again, leading to recurring “data cleanup projects” that eat away at productivity.
Closing the gaps in Salesforce’s native reactive cleansing
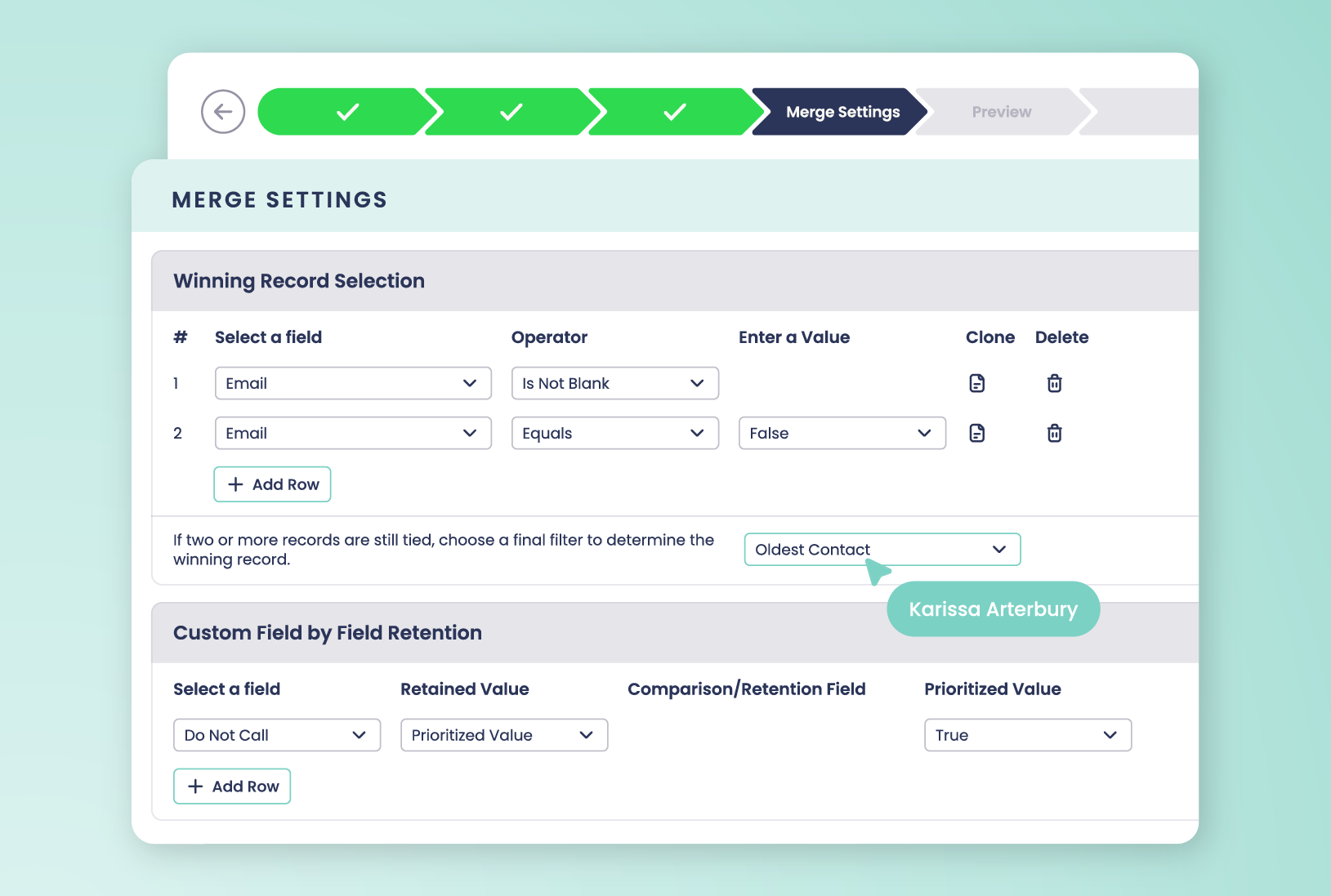
Native Salesforce can merge small sets of duplicates, but it struggles with large-scale cleanups — whether from years of neglected data, territory reshuffles, CRM migrations, or the record overlap that often follows mergers and acquisitions.
These scenarios can leave tens of thousands of records in conflict, and native tools simply can’t resolve that volume quickly or accurately.
Closing those gaps means introducing automation that can handle scale, complexity, and nuance without sacrificing accuracy. Complete Clean delivers that by:
- Merging thousands of records across any Salesforce object, including custom ones, without exporting data or relying on Data Loader.
- Leveraging multiple tiebreakers to resolve complex duplicates, even when records have overlapping or conflicting details.
- Providing merge previews so you can see exactly how records will change.
- Letting you undo a merge and restore records from the Salesforce recycling bin if you want to roll changes back.
- Preserving data security by operating 100% natively in Salesforce.
With the right automation and reactive processes in place, cleanup stops being a dreaded and disruptive one-off project and becomes a routine part of maintaining data integrity.
| Native Salesforce Reactive Cleansing vs Automated Solutions | ||
|---|---|---|
| Native Salesforce Tools | Complete Clean / Complete AI | |
| Merge Capacity | Merge up to 3 records at a time, only for Accounts, Contacts, and Leads. | Mass-merge thousands of records at once across standard and custom objects. |
| Object Coverage | Limited to standard objects; custom objects require Apex or manual cleanup. | Supports any Salesforce object out of the box, including custom ones. |
| Survivorship Rules | Admins manually pick field values during every merge; no automation. | Configurable survivorship, field-by-field retention, and multiple tiebreakers. |
| Bulk Processing | Requires CSV exports, offline cleanup, and reimports with Data Loader. | Runs natively inside Salesforce, no exports or external files required. |
| Data Import Wizard | Cap of 50,000 records, 100MB file limit, no dedupe or normalization support. | Handles millions of records, dedupes and standardizes automatically. |
| Data Loader | Supports large volumes but requires technical know-how and offline prep. | Drag-and-drop flows with built-in enrichment, dedupe, and field rules. |
| Error Handling | Error logs must be reviewed and corrected manually after each job. | Preview merges, rollback options, and AI validation reduce rework. |
| Integration Awareness | Duplicate and validation rules often bypassed by imports or API feeds. | Applies cleansing and matching consistently across imports, APIs, and enrichments. |
| Global Readiness | No native support for global phone or address normalization. | Formats fields like phone numbers and countries into global standards automatically. |
| Security & Compliance | Often requires exporting sensitive data to CSVs, adding risk and overhead. | 100% Salesforce-native; data never leaves your org. |
| Time to Value | Weeks or months of cleanup projects before value is realized. | Immediate wins from automation; clean data in hours, not weeks. |
Want to Start Cleaning Your Salesforce Data, But Unsure Where to Begin?
Get your Step-by-Step Guide to Deduplicating Your CRM and learn how to spot, merge, and prevent duplicates using the same strategies trusted by leading enterprises and Salesforce consultants.
Download Your Free Guide Now
5 Salesforce Data Cleansing Best Practices
Proactive and reactive data cleansing go hand in hand: one prevents problems, the other repairs them. But the real magic happens when they work together as a system.
These 6 Salesforce data cleansing best practices show you how to turn both approaches into a sustainable routine that keeps your Salesforce data clean, accurate, and actionable.
1. Treat Salesforce data cleansing as an ongoing process, not a one-off project
It’s easy to approach data cleansing like household spring cleaning — intense, infrequent, and exhausting. But unlike your house, Salesforce doesn’t stay clean for long, and the symptoms of a dirty environment aren’t nearly as obvious.
The longer you wait, the harder it is to get things back under control.
That’s why Salesforce data cleansing (and household cleaning) works best as a recurring rhythm.
So instead of waiting for problems to pile up, establish a monthly or quarterly maintenance routine. Mix quick, lightweight tasks — like spot-checking duplicates, validating enrichment freshness, and reviewing incomplete records — with deeper processes like bulk merges and mass deduplications once a quarter.
2. Close the loop every time your data changes
Cleaning data is one part of the process.
After you merge, match, or update your records, you have to make sure those changes cascade through your routing and ownership logic. Otherwise, even the cleanest data becomes stale in practice.
Imagine you merge two duplicate accounts. If Salesforce doesn’t re-evaluate who owns the consolidated record, you could end up with two active opportunities tied to the wrong rep, or worse, assigned to someone who’s no longer with your team.
The same problem happens when enrichment updates a region or field: that one change might mean the account belongs to a completely different territory or team.
In this context, closing the loop means creating a routine (or better yet, automation) that listens for these changes and immediately reroutes, reassigns, or alerts the right people.
For example:
- When a merge completes, trigger an ownership check and update the record’s territory
- When enrichment adds new firmographic data, re-run lead-to-account matching
- When a rep goes out of office, use fallback routing to automatically reroute new inquiries to the next available queue
Automated solutions like Complete Leads give you extra leverage, extending your routing logic to work hand in hand with your data hygiene processes.
When you merge a lead or match it to an account, for example, you can configure Complete Leads to re-run routing rules, apply fallback logic for unavailable reps, and confirm assignment — all natively within Salesforce.
3. Build clean intake lanes for uploads and event lists
Event signups, webinar lists, and partner imports are carriers for dirty data. If you upload them without structure, you’re back to chasing duplicates and incomplete records.
That’s why your import process should follow the same balance of proactive and reactive cleansing you apply everywhere else.
In practice, this means that every upload should pass through two defined intake lanes:
- Proactive: normalizing fields, enforcing naming conventions, and requiring complete data before uploading.
- Reactive: flagging near duplicates, reviewing exceptions, and merging records immediately after import so issues don’t spread
After you’ve defined these routines, assign ownership.
Decide who reviews each upload, what thresholds trigger a manual check, and how often these reviews should happen. The goal is to make list imports a managed process, not an afterthought.
4. Enrich thoughtfully with audit trails and rollback options
Different data providers can deliver conflicting data, and one incorrect overwrite can cascade across related records.
ZoomInfo might update a company’s industry to “software,” while D&B lists it as “IT Services.” It’s a mismatch that looks small on paper, but one that can move accounts to the wrong segment, trigger wrong routing rules, and skew your reporting.
That’s why proper enrichment requires care, structure, and accountability. You need a process that decides what gets updated, when, and by whom.
For starters, proactively define your field hierarchy and source of truth.
Decide which provider “wins” when multiple sources fill the same field, and tag each update with the data provider name and timestamp. Doing so gives you transparency into where the data originated and how current it is.
Then, reactively run periodic checks to identify outdated or conflicting information and roll back changes that don’t meet your data standards.
But when multiple systems feed into your Salesforce environment, manually maintaining this level of control is difficult.
That’s where Complete Clean brings much-needed structure, helping you manage enrichment directly inside Salesforce by configuring survivorship rules for each field, prioritizing trusted data sources, and previewing merges before updates go live. You also get merge previews, tiebreaker logic, and rollback options.
Every change is traceable, so you can see who updated a field, when it happened, and whether you should keep or revert it.
5. Stay ahead of problems by tracking data hygiene signals that actually matter
A clean Salesforce environment looks tidy and tells you, in real time, when things start to slip. You don’t have to track everything, but you do have to stay on top of the metrics that reveal the health of your data (and automation processes).
A good place to start are the indicators that connect directly to your GTM performance:
Duplicate rate
Use Salesforce Duplicate Rules and Matching Rules to automatically flag duplicate records.
Salesforce stores these flags in the DuplicateRecordSet and DuplicateRecordItem objects, which means you can build reports to track:
- Number of potential duplicates by object (Lead, Contact, Account)
- Which object types (Leads, Contacts, Accounts) see the most duplication
- How many duplicate records are being flagged each week
- Duplicate rate as a percentage of total records
- Whether the duplicate rate is trending up or down over time
Duplicate spikes usually mean upstream processes are slipping. Think new reports bypassing validation or users creating manual records instead of converting leads.
Building reports off this rate tells you where dirty data enters your environment so you can fix the source, not just the symptoms.
Date completeness
Run reports on required fields (email, account owner, industry, etc.) to see which records are missing critical information.
Add field-level validation rules for must-have data, or use a simple custom formula field that scores data based on how many key fields are filled.
Over time, this gives you a quick visual for which objects need attention and where enrichment lags.
Lead response time (time-to-route)
You can calculate this with two fields:
- CreatedDate (when the lead entered Salesforce)
- A custom Assigned_Date__c timestamp (populated by Salesforce Flow when ownership changes)
Then create a formula field or report that subtracts the two to reveal the average routing speed.
Routing delays are often the first sign that your automation is misfiring. So if your time-to-route increases, it might mean your rules aren’t updating correctly after mergers or rep changes.
Field change activity
Use Field History Tracking or Audit Trail to monitor how often key fields (like Industry, Region, or Account Owner) change. Frequent or unexplained updates can signal conflicting enrichment sources or automation loops.
If you’re using Complete Clean, which logs every merge and field update, you can trace exactly when and why a value changed and roll it back if needed.
Record growth and decay
Salesforce doesn’t report on deleted records directly, but you can monitor overall data flow by tracking record creation trends.
Run a simple report grouped by Created Date (by week or month) for key objects like Leads or Accounts.
A sudden spike in new records might mean unvalidated imports and sync issues, while a drop could signal broken integrations or routing failures.
Put Salesforce Data Cleansing on Autopilot with Traction Complete

Even the best-run, enterprise Salesforce environments aren’t “set it and forget it.”
No matter how disciplined your team is, or how good your automations and tools are, Salesforce data quality will naturally erode over time from manual entry errors, system integrations, and shifting processes.
That’s why cleaning Salesforce data isn’t a one-time project, but a moving target.
Markets shift, accounts reorganize, and your own GTM motions evolve, so even the cleanest org today will need attention tomorrow.
Treat data stewardship as an ongoing discipline, not a one-time checkbox. The teams that scale with clarity are the ones that see cleansing as continuous: blending proactive guardrails with reactive cleanups so every workflow, report, and automation rests on a reliable foundation.
And because Traction Complete builds solutions 100% native to Salesforce, we understand the platform’s strengths, blind spots, and nuances better than anyone, giving RevOps teams the confidence their data stays clean where it matters most.

Stop Fixing Data. Start Trusting It.
Complete Clean keeps your Salesforce data reliable without spreadsheets, Data Loader jobs, or one-off cleanup projects. It continuously scans for duplicates across standard and custom objects, applies field-level rules to preserve accuracy, and cleans records at scale — all 100% inside Salesforce.
Give your team a CRM they can trust year-round, with clean data powering faster routing, better reporting, and confident decision-making.